







Kayo Magalhães / Câmara dos Deputados O Conselho de Comunicação Social é um órgão auxiliar

Kayo Magalhães / Câmara dos Deputados Boulos quer incentivar o controle social dos preços O Projeto

Renato Araújo / Câmara dos Deputados Fernando Rodolfo, autor da proposta O Projeto de Lei

Bruno Spada/Câmara dos Deputados Jonas Donizette é o autor da proposta O Projeto de Lei

Sebrae-SP realiza lançamento do programa Loja do Futuro para varejistas de Bragança Paulista A palestra

Edição 2025 da FE movimentou quase R$ 60 milhões em negócios No ano passado, a

Empresa afirma que desenvolveu uma plataforma proprietária e um ecossistema completo de gestão, buscando se diferenciar em um setor marcado pela expansão dos aplicativos de transporte e pelo uso de soluções white-label. O mercado brasileiro de mobilidade urbana vive um momento de forte expansão, impulsionado pelo aumento da demanda por transporte por aplicativo e pela popularização de plataformas digitais voltadas a motoristas e passageiros. Nesse cenário, diversas empresas passaram a oferecer soluções semelhantes às utilizadas por gigantes como Uber e 99, ampliando a concorrência em um segmento que movimenta bilhões de reais anualmente. Apesar da diversidade de marcas disponíveis, especialistas do setor apontam que existe uma diferença relevante entre empresas que desenvolvem sua própria tecnologia e aquelas que utilizam plataformas licenciadas de terceiros, conhecidas como soluções white-label. Enquanto esse modelo permite acelerar a entrada no mercado, o desenvolvimento de um software proprietário oferece maior autonomia para criar funcionalidades, realizar atualizações e adaptar o sistema às demandas do negócio. É justamente nesse posicionamento que a POP Move afirma concentrar sua estratégia de crescimento. Segundo a empresa, desde sua fundação a decisão foi investir no desenvolvimento de uma plataforma tecnológica própria, reunindo equipes de tecnologia, processos internos e uma estrutura voltada à evolução contínua do sistema. Tecnologia própria como estratégia de longo prazo O desenvolvimento de uma plataforma proprietária exige investimentos constantes em programação, infraestrutura, segurança digital, pesquisa, testes e atualização de funcionalidades. Além do aplicativo utilizado por motoristas e passageiros, esse processo envolve a criação de sistemas administrativos, integrações, arquitetura de dados e mecanismos de escalabilidade. Na avaliação da POP Move, controlar toda essa estrutura permite maior liberdade para implementar melhorias, responder rapidamente às necessidades do mercado e incorporar novas tecnologias, sem depender do cronograma de fornecedores externos. A empresa afirma que sua proposta vai além da disponibilização de um aplicativo de corridas, buscando construir um ecossistema tecnológico capaz de acompanhar a transformação da mobilidade urbana. Ecossistema de mobilidade Com a evolução do setor, os aplicativos deixaram de exercer apenas a função de conectar motoristas e passageiros. Hoje, plataformas de mobilidade precisam integrar diferentes recursos tecnológicos, como inteligência artificial, geolocalização em tempo real, sistemas de pagamento, segurança digital, atendimento automatizado, gestão operacional e análise de dados. Segundo a POP Move, sua plataforma foi estruturada para evoluir continuamente, permitindo a incorporação de novos serviços e funcionalidades à medida que o mercado se transforma. Essa flexibilidade, segundo a empresa, também favorece a adaptação às diferentes necessidades de cidades, parceiros e operadores que utilizam a tecnologia. Mais do que um aplicativo Outro ponto destacado pela empresa é o desenvolvimento de processos internos voltados à implantação, treinamento, suporte operacional e acompanhamento da gestão das operações. A POP Move afirma que, além da tecnologia, investiu na criação de metodologias próprias para apoiar a expansão da plataforma, buscando padronizar procedimentos e fortalecer a experiência tanto de motoristas quanto de passageiros. De acordo com a empresa, essa combinação entre tecnologia, operação e cultura organizacional representa um dos pilares da estratégia adotada. O papel da inovação A inovação também ocupa posição central no planejamento da companhia. A expectativa do setor é de que recursos baseados em inteligência artificial, automação de processos, análise preditiva de dados e novas formas de integração entre serviços tenham participação crescente na mobilidade urbana nos próximos anos. Nesse contexto, empresas que possuem domínio sobre o próprio desenvolvimento tecnológico tendem a ter maior capacidade para implementar melhorias de forma contínua e adaptar suas plataformas às mudanças do mercado. Segundo a POP Move, o objetivo é manter uma evolução permanente da tecnologia, investindo em novos recursos e no aprimoramento da experiência dos usuários. Critérios para avaliar uma plataforma Especialistas do mercado recomendam que empresas e investidores interessados em soluções de mobilidade observem aspectos que vão além da interface do aplicativo ou da quantidade de funcionalidades disponíveis. Entre os fatores considerados relevantes estão a existência de equipe própria de desenvolvimento, o controle sobre o código-fonte, a frequência das atualizações, a capacidade de inovação e a estrutura responsável pela manutenção da plataforma. Esses elementos podem influenciar diretamente a capacidade de evolução do sistema e a sustentabilidade da operação no longo prazo. Posicionamento Em um mercado cada vez mais competitivo, a POP Move busca consolidar sua atuação como empresa brasileira de tecnologia voltada à mobilidade urbana, sustentando sua estratégia em três pilares: desenvolvimento de plataforma própria, cultura organizacional estruturada e inovação contínua. Segundo a companhia, a proposta é construir um ecossistema tecnológico capaz de acompanhar a evolução do setor, fortalecendo sua presença no mercado por meio de investimentos em tecnologia, processos e desenvolvimento de soluções para mobilidade.

De uma startup criada no interior do Brasil para uma empresa presente em centenas de cidades e patrocinadora oficial de um dos eventos

Especialista destaca que o avanço da IA tende a automatizar tarefas repetitivas, criar novas oportunidades profissionais e ampliar o acesso a soluções personalizadas

A Advisory Board Institute lança o ABI Club para conectar empresários à experiência prática de um Board Consultivo, ajudando pequenas e médias empresas a

A Visa direcionou Claude Mythos, da Anthropic, para a infraestrutura por trás de bilhões de transações diárias, uma rede que abrange mais de

Por Cristiney Soares Tecnologia implementada pela Plataforma VANTIA registra eventos críticos dos leilões em blockchain, elevando o nível de segurança, governança e confiabilidade

Levantamento inédito com 1.200 respondentes revela uma demanda reprimida por moradias voltadas à longevidade ativa e embasa o lançamento da Housi Senior+ O Brasil tem 35

Snowflake announced Cortex AI Gateway on Tuesday, a centralized control layer designed to govern how AI agents — including those built by competitors

As mudanças promovidas pela Reforma Tributária já movimentam empresas de todos os portes, que precisam se adaptar a um novo cenário fiscal. Nesse
Silêncio do artista alimenta especulações nas redes sociais, enquanto equipe afirma que prioridade foi sua recuperação. Episódio reacende debate sobre os impactos da
Mais um domingo que começa com a nossa tradicional lista de indicações de games da semana, para te ajudar a escolher o que
Kayo Magalhães / Câmara dos Deputados O Conselho de Comunicação Social é um órgão auxiliar do Congresso Nacional O Conselho de Comunicação Social

Der Schweizer Unternehmer Abraham Ackermann, Gründer von Telemedia Brasil und CEO der Lighthouse AG, absolvierte eine Reihe strategischer Treffen in Deutschland mit Unternehmern,

A busca por soluções para a queda de cabelo tem levado cada vez mais pessoas aos consultórios médicos. Entre os tratamentos disponíveis, o
O sábadão chegou e você já jogou tudo o que tinha disponível na biblioteca, incluindo os games gratuitos liberados pela Steam recentemente? Não
Kayo Magalhães / Câmara dos Deputados Boulos quer incentivar o controle social dos preços O Projeto de Lei 4788/25, do deputado licenciado Guilherme Boulos

Engenheiro, gestor e líder na área de tecnologia e energia, José Israel de Almondes construiu uma carreira marcada por grandes projetos, formação internacional

Quase todo mundo conhece a sensação de não querer estar do jeito que está. Você fica triste e logo se pergunta o que
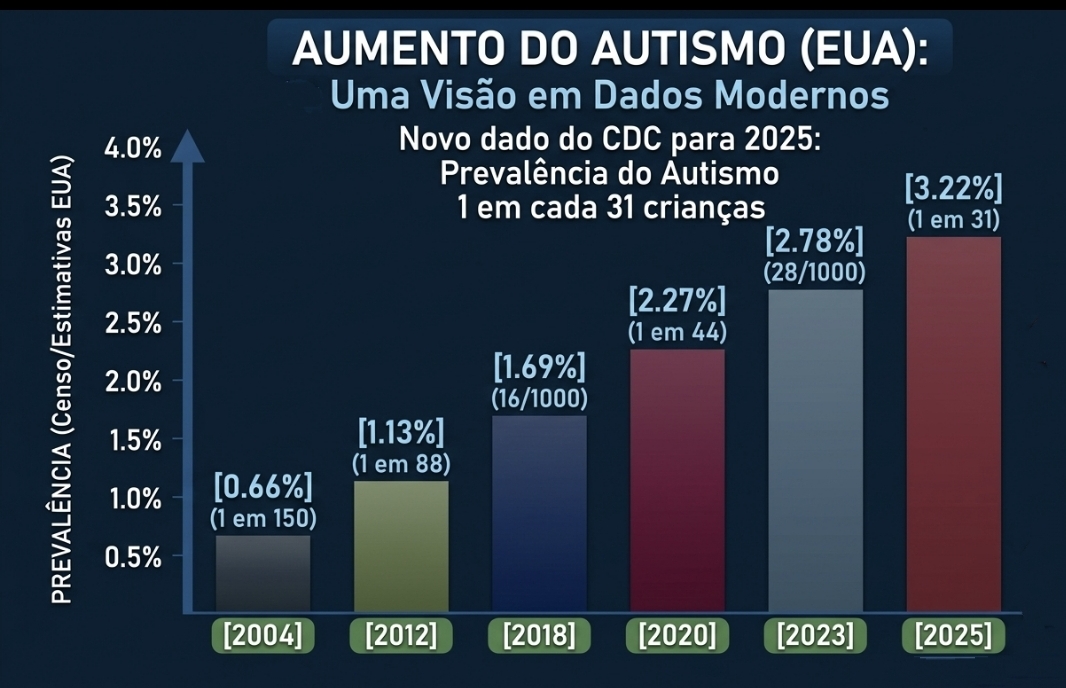
Psiquiatra BH, Dr Márcio Candiani, TDAH e Autismo Crescimento dos casos reflete avanços nos critérios diagnósticos, maior conscientização e identificação de perfis antes

Criada pela empreendedora Pollyana Valadão, de São José dos Campos, a plataforma reúne calendário menstrual, telemedicina, treinos, organização de rotina e marketplace em

Queda recorrente da confiança do consumidor contrasta com novos investimentos no mercado de luxo e reforça a necessidade de abandonar descontos generalizados O






