Vinicius Loures/Câmara dos Deputados Saulo Pedroso: transparência fortalece o controle social A Comissão de Desenvolvimento

Kayo Magalhães / Câmara dos Deputados Cleber Verde: exclusão digital acentua desigualdades sociais A Comissão

Renato Araújo/Câmara dos Deputados Hugo Leal, relator da proposta na comissão A Comissão de Viação

Kayo Magalhães / Câmara dos Deputados Rodrigo da Zaeli recomendou a aprovação do projeto A
(Freepik/Reprodução) Continua após publicidade O Departamento Estadual de Trânsito de São Paulo (Detran) retirou o

O Inovatex – Programa de Inovação e Tecnologia da Indústria Têxtil e Confecção de Americana
Até agora, muitas empresas já implantaram alguma forma de RAG. A promessa é sedutora: indexe seus PDFs, conecte um LLM e democratize instantaneamente seu conhecimento corporativo. Mas para as indústrias dependentes da engenharia pesada, a realidade tem sido desanimadora. Os engenheiros fazem perguntas específicas sobre infraestrutura e o bot tem alucinações. A falha não está no LLM. A falha está no pré-processamento. Os pipelines RAG padrão tratam os documentos como sequências simples de texto. Eles usam "fragmentação de tamanho fixo" (cortando um documento a cada 500 caracteres). Isto funciona para a prosa, mas destrói a lógica dos manuais técnicos. Ele corta as tabelas ao meio, separa as legendas das imagens e ignora a hierarquia visual da página. EUmelhorar a confiabilidade do RAG não significa comprar um modelo maior; trata-se de consertar o "dados escuros" problema por meio de fragmentação semântica e textualização multimodal. Aqui está a estrutura arquitetônica para construir um sistema RAG que possa realmente ler um manual. A falácia do chunking de tamanho fixo Em um tutorial padrão do Python RAG, você divide o texto por contagem de caracteres. Em um PDF empresarial, isso é desastroso. Se uma tabela de especificação de segurança abrange 1.000 tokens e o tamanho do seu bloco é 500, você acabou de dividir o "limite de tensão" cabeçalho do "240V" valor. O banco de dados vetorial os armazena separadamente. Quando um usuário pergunta, "Qual é o limite de tensão?"o sistema de recuperação encontra o cabeçalho, mas não o valor. O LLM, forçado a responder, muitas vezes adivinha. A solução: fragmentação semântica O primeiro passo para corrigir o RAG de produção é abandonar a contagem arbitrária de caracteres em favor da inteligência documental. Utilizando ferramentas de análise com reconhecimento de layout (como o Azure Document Intelligence), podemos segmentar dados com base na estrutura do documento, como capítulos, seções e parágrafos, em vez da contagem de tokens. Coesão lógica: Uma seção que descreve uma peça específica da máquina é mantida como um único vetor, mesmo que varie em comprimento. Preservação da mesa: O analisador identifica um limite de tabela e força toda a grade em um único bloco, preservando as relações linha-coluna que são vitais para uma recuperação precisa. Em nossos benchmarks qualitativos internos, passar da fragmentação fixa para a semântica melhorou significativamente a precisão da recuperação de dados tabulares, interrompendo efetivamente a fragmentação das especificações técnicas. Desbloqueando dados visuais escuros O segundo modo de falha do RAG empresarial é a cegueira. Uma enorme quantidade de IP corporativo não existe em texto, mas em fluxogramas, esquemas e diagramas de arquitetura de sistema. Modelos de incorporação padrão (como text-embedding-3-small) não podem "ver" essas imagens. Eles são ignorados durante a indexação. Se a sua resposta estiver em um fluxograma, seu sistema RAG dirá: "Não sei." A solução: textualização multimodal Para tornar os diagramas pesquisáveis, implementamos uma etapa de pré-processamento multimodal usando modelos com capacidade de visão (especificamente GPT-4o) antes que os dados cheguem ao armazenamento de vetores. Extração de OCR: O reconhecimento óptico de caracteres de alta precisão extrai rótulos de texto de dentro da imagem. Legendagem generativa: O modelo de visão analisa a imagem e gera uma descrição detalhada em linguagem natural ("Um fluxograma mostrando que o processo A leva ao processo B se a temperatura exceder 50 graus"). Incorporação híbrida: Esta descrição gerada é incorporada e armazenada como metadados vinculados à imagem original. Agora, quando um usuário pesquisa por "fluxo de processo de temperatura," a pesquisa vetorial corresponde ao descriçãomesmo que a fonte original fosse um arquivo PNG. A camada de confiança: UI baseada em evidências Para adoção empresarial, a precisão é apenas metade da batalha. A outra metade é verificabilidade. Em uma interface RAG padrão, o chatbot fornece uma resposta em texto e cita um nome de arquivo. Isso força o usuário a baixar o PDF e procurar a página para verificar a reivindicação. Para consultas de alto risco ("Este produto químico é inflamável?"), os usuários simplesmente não confiarão no bot. O a arquitetura deve implementar citação visual. Como preservamos o link entre o bloco de texto e sua imagem pai durante a fase de pré-processamento, a IU pode exibir o gráfico ou tabela exato usado para gerar a resposta junto com a resposta de texto. Esse "mostre seu trabalho" O mecanismo permite que os humanos verifiquem o raciocínio da IA instantaneamente, preenchendo a lacuna de confiança que mata tantos projetos internos de IA. Preparado para o futuro: incorporações multimodais nativas Enquanto o "textualização" (converter imagens em descrições de texto) é a solução prática para hoje, a arquitetura está evoluindo rapidamente. Já estamos vendo o surgimento de incorporações multimodais nativas (como o Embed 4 de Cohere). Esses modelos podem mapear texto e imagens no mesmo espaço vetorial sem a etapa intermediária de legendagem. Embora atualmente utilizemos um pipeline de vários estágios para controle máximo, o futuro da infraestrutura de dados provavelmente envolverá "ponta a ponta" vetorização onde o layout de uma página é incorporado diretamente. Além disso, como LLMs de contexto longo tornar-se rentável, a necessidade de fragmentação pode diminuir. Em breve poderemos passar manuais inteiros para a janela de contexto. No entanto, até que a latência e o custo das chamadas de milhões de tokens caiam significativamente, o pré-processamento semântico continua a ser a estratégia economicamente mais viável para sistemas em tempo real. Conclusão A diferença entre uma demonstração RAG e um sistema de produção é como ele lida com a realidade confusa dos dados empresariais. Pare de tratar seus documentos como simples sequências de texto. Se você deseja que sua IA entenda seu negócio, você deve respeitar a estrutura de seus documentos. Ao implementar a fragmentação semântica e desbloquear os dados visuais em seus gráficos, você transforma seu sistema RAG de um "pesquisador de palavras-chave" em um verdadeiro "assistente de conhecimento." Dippu Kumar Singh é arquiteto de IA e engenheiro de dados. Fonte ==> Cyberseo

Ouça o artigo 2 minutos Este áudio é gerado automaticamente. Por favor, deixe-nos saber se você tiver comentários. Resumo de mergulho: Heinz está

O laboratório de IA Arcee, com sede em São Francisco, causou sensação no ano passado por ser uma das únicas empresas dos EUA

Ouça o artigo 4 minutos Este áudio é gerado automaticamente. Por favor, deixe-nos saber se você tiver comentários. Applebee’s está trazendo de volta

Um novo estudo do Google sugere que modelos de raciocínio avançados alcançam alto desempenho ao simular debates do tipo multiagentes envolvendo diversas perspectivas,

De um carro chamado por aplicativo para uma reunião ao almoço entregue por um ciclista habilidoso no trânsito, a “uberização” se infiltrou em

Ouça o artigo 3 minutos Este áudio é gerado automaticamente. Por favor, deixe-nos saber se você tiver comentários. Resumo de mergulho: A Crocs
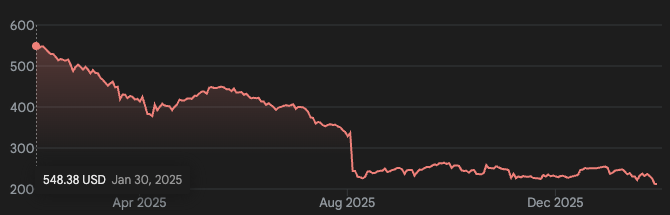
A startup Factify, sediada em Tel Aviv, emergiu hoje do sigilo com uma rodada inicial de US$ 73 milhões para uma missão ambiciosa,

Quando a crise estoura, o feed desaparece. O que fica é o histórico — e a reputação registrada na imprensa passa a decidir quem se defende e quem fica exposto.

Por Júlio Cezar Vilela Pereira Foi no campo de batalha, em quase três décadas de dedicação exclusiva à Polícia Militar de Minas Gerais,

O professor, pesquisador e profissional da saúde Éder Júlio Rocha de Almeida lança o livro Autismo, medo e afeto: Humanização no atendimento odontopediátrico,

Lançamentos reforçam a união entre tecnologia, ciência e prática clínica Com o IMCAS Paris em pleno andamento, a Fotona Brasil se destaca como
O cloud gaming, ou jogatina na nuvem, é um formato de transmissão que permite jogar títulos de alta qualidade sem precisar de um

Empresa apresenta protocolos brasileiros em meio ao maior encontro mundial da especialidade A medicina regenerativa e estética vive um momento de profunda transformação,

A tradicional K.L.A. Educação Empresarial anuncia o Congresso Nacional de Vendas 2026, evento que deve reunir líderes de equipes comerciais, gestores, executivos, empresários

Nascido em 1984, em Conselheiro Lafaiete, Minas Gerais, Alex Lage vem se consolidando como um dos nomes em ascensão na educação tecnológica e

Reconhecido nacionalmente por sua atuação como empresário e palestrante, Ricardo Cattani dá um novo passo em sua trajetória profissional e estreia na área
Vinicius Loures/Câmara dos Deputados Saulo Pedroso: transparência fortalece o controle social A Comissão de Desenvolvimento Urbano da Câmara dos Deputados aprovou proposta que

O alisamento capilar, por muito tempo associado a procedimentos padronizados e pouco cuidadosos, vem passando por uma transformação significativa no mercado da beleza.

Em um mundo onde a experiência do cliente e a reputação institucional caminham lado a lado, profissionais que dominam a arte da presença,

Especialista alerta que falta de organização patrimonial ainda é uma das principais causas de disputas judiciais entre herdeiros O Direito de Família e